on
Logistic vs Linear. Why Sigmoid?
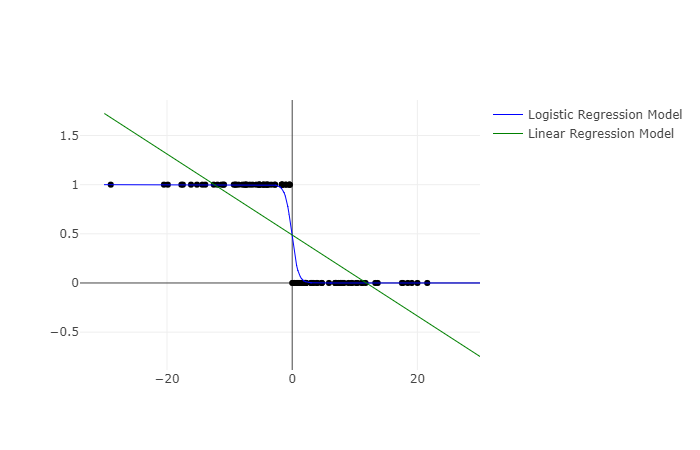
I have been asked many times that why do we need logisitic regression and sigmoid function. Why can’t we simply fit a linear regression. Here is what I think sigmoid function makes sense for classification task.
-
When I am trying to classify, I would like it if I can express my confidence with some probability. Sigmoid function has a range between 0 and 1. So we can get a probability score for a class. This is very handy for classification. We can simply classify it to class 1 or 0 based on probability score (1 if p>0.5 in general).
-
In linear regression, we generally fit a line by minimizing root mean square error RMSE. Now think of points at extreme end. These points will be away from the fitted line and contribute most to the loss function. For a regression task, it makes sense. But for classification, these points should contribute least cost to the loss function. They are easily classified with their respective class and they lie away from the discriminant boundary.(x=0 in above image). With sigmoid function we won’t get this issue. Points at extreme ends are very well classified and their predicted probability will be 1. To fit a logistic regression, we minimize Cross Entropy Error Function. So these extreme points will contribute almost 0 [log(1)] to cost function. This is one very important advantage we get by using logistic regression with cross entropy loss instead of linear regression and root mean square error.